What are the conditions under which very different words are brought together in writing? Are varied word combinations predisposed to particular genres or discourses? Are there types of words that could be said to constitute lexical situations that would not otherwise occur? And, when words that are not typically used in the same context co-occur, what are they doing? I am going to report the results of a text analysis experiment designed to begin to address these questions. Recent advances in semantic modeling (from topic modeling to word embeddings) make it relatively easy to describe the statistical likelihood of a given set of words to co-occur. Methods in semantic modeling start from the premises that words tend to occur in particular linguistic contexts, and we can decipher the meaning of an unknown word based upon the words that appear near it. While many humanists (like me) interested in text analysis have begun to explore the mathematics of operationalizing these premises, corpus linguists have been thinking about modeling language in this way since the 1940s and 50s. Early theorist of the “distributional structure” of language, Zellig Harris, explains that, “The perennial man in the street believes that when he speaks he freely puts together whatever elements have the meanings he intends; but he does so only by choosing members of those classes that regularly occur together and in the order in which these classes occur.”1 His contemporary, J. R. Firth, put the claim even more plainly in his now famous formulation: “You shall know a word by the company it keeps.”2 Since these foundational theories, linguists have produced methods for mathematically representing the tendencies of language. In this experiment, I focus on word space models, which represent the distribution of words in a corpus as vectors with hundreds or thousands of dimensions wherein proximity in the vector space corresponds to semantic similarity. The vector position for any given word represents a probabilistic profile regarding the lexical contexts in which one would expect to find that word. As a consequence, word vectors can be added and subtracted to find the words most similar in the model to the resulting composite vector.
Two different semantic contexts of ‘bounds’ - The values appearing next to the resulting words refer to the cosine similarity score between the composite vector (produced by adding the positive word vectors and subtracting the negative one) and the most similar word vectors in the word space model. The score indicates the proximity of the vectors in the model, which should correspond to their semantic similarity—the closer to 1, the more similar words.
print(model.most_similar(positive=['bounds', 'leaps'], negative=['limits'])[:6])
print()
print(model.most_similar(positive=['bounds', 'limits'], negative=['leaps'])[:6])
[('skips', 0.5588804483413696), ('leap', 0.5247325897216797), ('leapt', 0.5211300253868103), ('skipping', 0.5187863111495972), ('flings', 0.5138592720031738), ('alights', 0.5134779810905457)]
[('boundaries', 0.6185899376869202), ('limited', 0.595120906829834), ('limit', 0.5744596719741821), ('precincts', 0.5576064586639404), ('confined', 0.5283891558647156), ('confine', 0.5277968645095825)]
Any particular phrase or sentence will feature word combinations that more or less correspond to linguistic patterns represented in the word space model. Defining expectation in terms of the proximity between word vectors, what are the contexts in which unexpected words tend to occur? Do they appear in particular places, like those rare neighborhood bars that attract patrons across a wide demographic range? Or are aberrational word groupings brought together by specific terms, like Prince or Beyoncé drawing fans from all backgrounds?
I come to semantic modeling from a literary perspective. I initially started to think about measures for unusual linguistic situations as potentially indexing the appearance of literary tropes and figures. It’s a simplistic hypothesis, but it still seems reasonable to expect that unusual word combinations may be responsible for literal and figurative dimensions of meaning. The term heart often appears in discussions of biology as well as love; thus it may also appear in a context wherein both connotations obtain. Literary scholars have recently used semantic modeling to observe genre differences between fiction, poetry, and non-fiction as well as between sub-genres of the novel or particular forms of poetry during different historical periods.3 This experiment draws upon this previous work but frames the critical questions both more narrowly and broadly in particular ways. On the one hand, I’m looking at the co-occurrence of words on the level of the sentence. Given the distribution of words across a large corpus, how likely are the words in a given sentence to co-occur? On the other hand, I’m considering all of the sentences in a corpus (rather than focusing on specific genres) in order to move from mathematical properties of word distributions to observations about how those properties manifest as linguistic functions in different discursive contexts. From this perspective, it is not at all clear that literary texts would stand out from a broader print environment in the ways we might expect. Literary, or imaginative, writing may even appear more formulaic and orderly than written forms that rely on direct, empirical observation. (I’ll be primarily using imaginative writing in place of the term literature since the latter is anachronistic for the seventeenth-century corpus used in this experiment.) According to the literary theorist Roland Barthes, the challenge for the novel writer, for one, concerns, “how to pass from Notation, and so from the Note, to the Novel, from the discontinuous to the flowing (to the continuous, the smooth [au nappé])?”4 Notation here refers to annotating one’s experience—recording a series of events and thoughts that appear together without the linguistic architecture that gives language the statistical character that Harris and Firth describe. Translating the discontinuous record of consciousness into linear prose means moving “from the fragment to the nonfragment” (18).
As the title of this post suggests, notation turns out to be very useful for explaining how the most unlikely linguistic situations are produced and organized in my corpus. I’m working with the publicly released portion of the Early English Books Online Text-Creation Partnership (EEBO-TCP), which consists of about 25,000 texts printed between 1475 and 1700. For this corpus, the preliminary answer to my opening string of questions is: there are particular terms that appear in the context of highly varied lexical contexts much more frequently than others, and these tend to be notational terms operating in a range of technical discourses (including heraldry, medicine, ornithology, and botany among others). Notation often refers to specific systems of signs and symbols used within a discipline like mathematics or music, but it can also be used in the manner that Barthes uses it above, to mean note-taking or annotating more generally. Most of the terms and contexts that I will present are best characterized by the first definition, but I will be using notation broadly to encompass both possible meanings because they each refer to processes of collecting unlike things—quantities, ideas, or observations—producing what Barthes calls “a layered text, a histology of cutups, a palimpsest.”5 In seventeenth-century English print, the language of notation performs this function by serving as a linguistic framework of arrangement and combination (as in a list of ingredients for a medical recipe) without requiring the grammatical entailments of linear prose. Considered from a literary historical perspective, the linguistic work of notation offers a useful point of contact for thinking about forms of abstraction and comparison, which produce the conditions under which disparate things are brought together in language. In the case of imaginative writing, we typically ascribe such tasks to tropes and figures, but critical theorists like Barthes and more recently literary historians, including Henry Turner, Elaine Freedgood, and Cannon Schmidt have drawn attention to the function of “technical, denotative, and literal” language in literary works.6 As I unpack the results of this experiment, I will locate different forms of notation in relation to this critical conversation in order to highlight the imaginative functions of this mode of arranging language.
I produced a 300-dimension word space model of a portion of the EEBO-TCP corpus (all of the texts printed between 1640 and 1700, from the English Civil Wars through the Restoration and Revolution of 1688, consisting of 18,752 texts) using the word2vec package in python. (I will refer to this as my Restoration model.)7 Word2Vec uses a “shallow” neural network to generate a predictive word distribution model, rather than a count-based model. This approach makes it more efficient and easier to train, and some computer scientists argue that predictive word space models perform better than count-based ones, but this is a highly contested argument.8 The challenge of using a predictive model for dealing with historical semantics, however, is that the training process makes it difficult to track how a term’s vector profile changes over time. To deal with this issue, I’ve taken a five-year subset (from 1678-1682, during the period of the Popish Plot and Exclusion Crisis in England) of the corpus used to train the model, so that I can compare the usage of words in the subset to their vector profiles in the larger Restoration model. The experiment that I present here then considers which words, occurring in texts printed between 1678 and 1682, tend to appear in contexts featuring the most varied combinations of terms relative to the larger Restoration model. While the results only directly refer to the five-year window of the subset, they appear to indicate a pattern that holds for most of the 1670s and 80s, based on other early investigations.
In order to identify these results, I developed an average standard deviation measure (in collaboration with Michael Gavin) that takes every context window for a given term in the five-year subset and finds the standard deviation between each vector position across the 300 dimensions for each word vector that co-occurs in a particular context window. The measure returns the standard deviation of the word vectors in a context window of the term, and that measure is averaged across all of the context windows for the term. The average standard deviation value then provides a proxy for determining how varied the lexical contexts tend to be for each term in the subset corpus (normalized to remove rare terms).9 I also explored a method that used the average cosine similarity scores between a key term and the words in its context windows, which represents how likely that particular term would appear within its different contexts. The standard deviation measure, however, represents the variation between all of the words of the context window alone. As a consequence, the top scoring terms for the measure are not necessarily words that appear in the widest range of contexts; instead, the top terms are words that tend to appear in the most uncommon contexts in the subset overall. These are the words that most frequently occur at the center of rare word sequences.
To see what this looks like, here are the top 50 terms returned for the average standard deviation measure for the 1678-1682 subset corpus:
Top 50 terms for average standard deviation measure
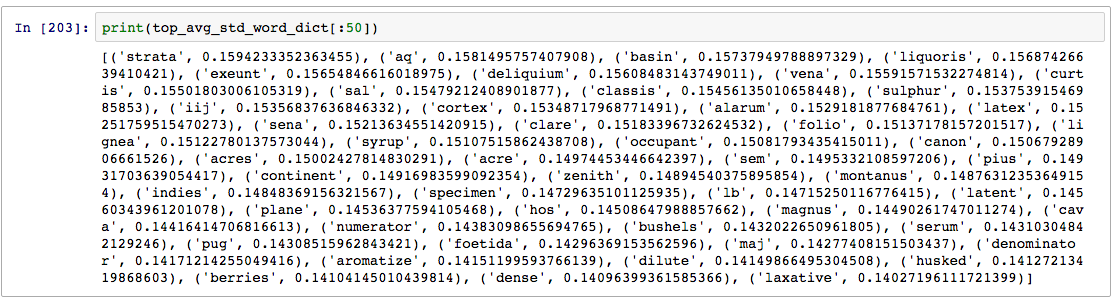
Since I am using a seventeenth-century corpus that includes Latin, English, and French texts including non-standardized spelling, these results look a bit inscrutable at first. I’ve gone through the most common texts in which each term appears in the corpus, and here is a breakdown of the different kinds of words in the top 50 that makes it easier to observe similarities across the terms:
Word Types in the Top 50 Terms
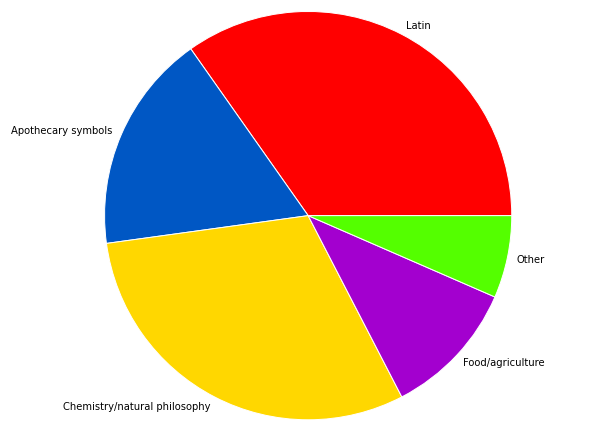
From these types, I can make some basic observations. First, the terms primarily come from different technical discourses, including medicine, natural philosophy/alchemy, and cooking/agriculture. These tend to be learned contexts featuring a high prevalence of abstruse language. In part because of the association with expert communities, the terms appear in genres that often combine English and Latin. While I was initially tempted to dismiss Latin terms because they appear in a foreign language context (and thus will unavoidably seem more varied in relation to a primarily English corpus), the Latin words are often performing a similar semantic function to the English terms on the list. Of course, the foreign language context is still a factor here, but I will suggest below that it’s not sufficient to explain the placement of the top terms on the list. What’s more is that it’s not practical to simply remove the Latin texts from the corpus because most of the terms are coming from genres that contain Latin and English in the same context, such as botany and ornithology. An unavoidable feature of seventeenth-century English print is that it is a multilingual environment.
Cluster of Top 150 Terms appearing in the Most Varied Contexts
To gain more context regarding the sources of the terms, I performed K-means cluster analysis on all of the context windows for the top 150 terms. This meant treating all of the context windows for each term as a single document and then seeing which of the ‘term documents’ are the most similar. This is not far off from the logic behind training a word vector model, and it similarly produces a result in which words that appear in similar contexts are located near one another and far from words appearing in dissimilar contexts. In the two-dimensional representation of the clusters, we can see that bushel, bushels, wheat, and barly are near one another in the upper-left corner, and fraction, numerator, and denominator are clustered in the bottom-right corner. In the word2vec model, fraction returns a similarity score of 0.81 with numerator and 0.82 with denominator, and numerator and denominator return a score of 0.94—all of which indicate very high semantic similarity between the terms and thus suggest that the k-means graph accurately reflects the proximity between terms in the larger word space model.
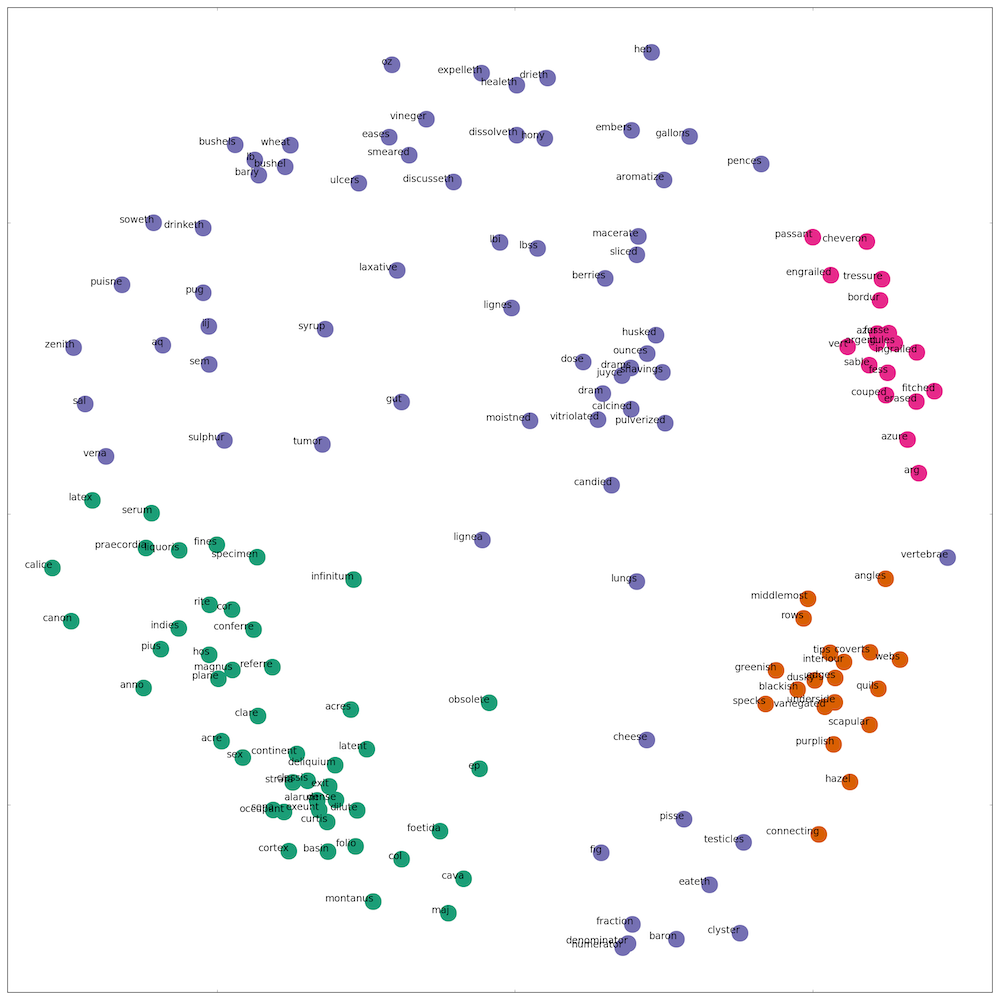
In k-means clustering (as with many topic modeling algorithms), the user has to select the number of clusters, and here I settled on four after identifying the top texts in which the words appeared in the subset. There appear to be four loose discourses in which these terms primarily occur. The table below breaks down the contents of these discourses:
| Cluster | Discourse | Exemplary Titles | Top Terms |
|---|---|---|---|
| Green | Latin texts primarily on botany and natural history | Robert Morison, Plantarum historiæ universalis Oxoniensis. Pars secunda seu herbarum distributio nova, per tabulas congnationis & affinitatis ex libro naturæ observata & detecta (1680) | folio, sine, sit, major, species, minor, anno, sex, alias |
| Sir Robert Sibbald, Scotland illustrated, or, An essay of natural history in which are exquisitely displayed the nature of the country, the dispositions and manners of the inhabitants…and the manifold productions of nature in its three-fold kingdom, (viz.) vegetable, animal and mineral, dispersed throughout the northern part of Great Brittain (1684) | |||
| Orange | Orinthology | John Ray, The ornithology of Francis Willughby of Middleton in the county of Warwick Esq, fellow of the Royal Society in three books : wherein all the birds hitherto known, being reduced into a method sutable to their natures, are accurately described (1678) | feathers, white, black, colour, middle, tips, dusky, exteriour, outmost |
| John Josselyn, New-Englands rarities discovered in birds, beasts, fishes, serpents, and plants of that country (1672) | |||
| Pink | Heraldry | Sir George Mackenzie, The science of herauldry, treated as a part of the civil law, and law of nations wherein reasons are given for its principles, and etymologies for its harder terms. (1680) | three, argent, betwixt, azur, sable, bend, within, beareth, quartered |
| Robert Thoroton, The antiquities of Nottinghamshire extracted out of records, original evidences, leiger books, other manuscripts, and authentick authorities : beautified with maps, prospects, and portraictures (1677) | |||
| Purple | Chemistry, medicine, and recipe books | Moses Charras, The Royal Pharmacopoea; Galenical and Chemical, according to the practice of the the most eminent and learned physicians of France (1678) | half, ounce, two, dram, three, iij, bushels, ounces |
| George Hartman, The true preserver and restorer of health being a choice collection of select and experienced remedies for all distempers incident to men, women, and children: selected from and experienced by the most famous physicians and chyrurgeons in Europe: together with Excellent directions for cookery (1682) |
Above I observed the prevalence of terms from technical discourses, and here we can see the kinds of texts in which these discussions occur. The titles indicate writers attempting to share different bodies of knowledge using specific taxonomies and systems of notation, as illustrated in the “science of herauldry” and an “essay of natural history.” The taxonomies are often attributed to a particular person or group, which creates the need to translate an individual system into the terms of a larger domain of shared knowledge. The top terms indexing the most varied contexts for each discourse include adjectives and numbers, but the most common type of terms, appearing across the clusters, are ones that seem to function as common ligatures used in descriptions of different cases and examples positioned within the respective taxonomies and systems. In ornithology, all species of birds have an exterior, feathers, and tips with features that are outmost or in the middle. Likewise, in natural histories written in Latin, different species are arranged in hierarchical structures with major and minor divisions. The purple cluster features a large amount of mathematical (fraction, denominator) and natural philosophical (vitriolated, pulverized) terms but also a significant number of units of measure and symbols (ounces, drams, gallons, iij, aq). While the latter terms belong to specific notational systems, the former also tend to appear in notational contexts.
Turn to particular passages with high frequencies of notational terms, and one can observe the linguistic and epistemological functions that they perform to make highly varied contexts possible. Notational terms provide the linguistic mortar for producing technical conventions—the descriptors, transitions, and abstract units that recur in lists and tables of various early modern knowledge domains. Take the following recipe for a Powder of Crabs-Claws from The Royal Pharmacopoea (1678). The recipe is set apart from the main text as a list, written in Latin and English in side-by-side columns, with each unit of the ingredients expressed in various apothecary symbols. Although in typical conversation or writing a seventeenth-century Briton would be unlikely to mention river crabs-eyes, white amber, deer’s heart-bone, and saffron in the same context, the genre of the recipe and the notational format that accommodates it make these very unlike objects linguistically and literally combinable.
")
In a radically different context, we can observe key terms from heraldry performing a similar function in the description of various coats of arms. Like the recipe, the table of noblemen and their coats of arms is represented in a distinctive printed form—set apart and arranged in a orderly manner, and, as in the recipe, there are particular recurring terms indicating the similarities across various coats even if the contents of the individual coats would be unlikely to appear together in a different context. These terms describe common colors and forms: for instance, arg. (the abbreviation for argent meaning silver), passant (the term for animals depicted in a walking position), and azure, as well as other terms, such as betwixt and within, indicate common prepositions used to link the different components of the coats.
")
Across disciplinary contexts, notation operates as a form of writing for translating subjective, potentially idiosyncratic observations into shared, intelligible systems of arrangement. Previous discussions of notation from a literary theoretical vantage have emphasized the “reality effect”10 produced by including denotative details in fictional contexts, and, more recently, Elaine Freedgood, Cannon Schmitt, and others have explored the potential for “literalist” readings of denotative language in literary texts.11 A literalist reading relies on tracking down references to outside knowledge domains, such as discussions of coal mining in Emile Zola’s Germinal or scientific language in George Elliot’s novels. This approach recognizes that insofar as novelists and poets represent characters participating in practices and crafts of the world, they unavoidably and intentionally introduce disciplines foreign from the experience of the reader. Like systems of notation, literary genres bring together disparate ideas and things. In highlighting notational language in non-literary contexts, I’m not suggesting that one should read recipes, blazons, or scientific tables as literary texts. Instead, I’m attempting to point out that notational contexts perform literary functions of combination, abstraction, and comparison, and recognizing such functions suggests new ways forward in describing how literary tropes and figures operate in relation to the layered format of notational lists and charts.
Consider my favorite exemplary passage of notational language, a recipe for a horse-hoof unguent that appears in a 1686 hunting manual, called The Gentleman’s Recreation.
")
The list of ingredients includes items that are familiar to us but would have been relatively novel to seventeenth-century readers (such as turpentine, which seems to have grown in popularity in the period) as well as objects completely foreign to us but very popular in the period (such as trayn oil). (Not to mention ones that are just baffling like dog’s grease, which turns out to be exactly what it sounds like.) These distinctive relationships between the objects in the recipe and our historical perspective indicate the varied meanings of the objects, beyond semantic significance. An item like train oil, which was produced by harvesting the fat from whale or cod, registers multiple dimensions of meaning in social and political domains in addition to linguistic ones. Indeed, historian K. G. Davies reports that in the 1680s, the Dutch government sent almost 2,000 whaling ships to Greenland to catch 10,000 whales for the production of train oil.12 The combination of highly varied words in this example supports the idea that the lexical variation accommodated by notational contexts corresponds to related non-linguistic features—so-called real world consequences. The recipe bears out Barthes’s view of notation as “palimpsest,” wherein multiple semantic domains correspond to multiple historical temporalities. The constellation of disparate ingredients brings together the cultural, social, economic, and colonial histories of early modern Europe. At the moment of composition, the recipe conveyed a technique for creating a new substance out of many different ones, but as a historical document it represents a unique juncture, indicating something that could only have been conceived at a specific moment in time.
The larger point is that the linguistic work of gathering together very different words indexes many more types of work that extend beyond the page and are implied by the histories of the objects and systems of notation represented. This linguistic phenomenon represents one answer to the question posed by Bruno Latour, “how do we pack the world into words?”13 From a literary studies angle, I would slightly reframe the question to ask, how does imaginative writing pack the world into words similarly or differently from other modes and genres? In a discussion of mathematical thinking and the imagination, Arielle Saiber and Henry Turner posit that “imagination is that faculty of thinking that facilitates movement across systems of explanation that seem irreconcilable, and that, as a consequence, allows for new thoughts, new arguments, and new explanations to occur.”14 If this is the case, then what are the linguistic structures and tropes that make this movement possible? This experiment regarding lexical variation and word space models illustrates how the language of notation contributes to such movement. How might we identify other contributors and the imaginative work they accomplish?
References
1. Zellig Harris, “Distributional Structure,” The Structure of Language: Readings in the Philosophy of Language, ed. Jerry A. Fodor and Jerrold J. Katz (Englewood Cliff, NJ: Prentice-Hall, 1964), 34.
2. J. R. Firth, Papers in Linguistics,1934–1951 (London: Oxford University Press, 1957), 11.
3. Roland Barthes, The Preparation of the Novel: Lecture Courses and Seminars at the Collège de France [2003], 3rd ed. (New York: Columbia University Press, 2010), 18. Also for an extended analysis of how Barthes’s understanding of notation changed from “The Reality Effect” essay to The Preparation of the Novel lectures, see Rachel Sagner Buurma and Lauren Heffernan, “Notation After ‘The Reality Effect’: Remaking Reference with Roland Barthes and Sheila Heti,” Representations 125.1 (Winter, 2014), 80-102. This essay appears in the fantastic special issue of Representations on denotative and technical language in the novel. I cite the introduction below.
4. There’s of course a lot of great recent critical work using semantic modeling. For topic modeling, the Journal of the Digital Humanities 2.1 (Winter, 2012), special issue on the subject is a great place to start. For thinking about, linguistic patterns on the scale of the sentence, see Sarah Allison, et al., “Pamphlet 5: Style ate the Scale of the Sentence”,” (June 2013)[lit lab]. Useful introductions to word embeddings include Lynn Cherney’s site word embedding version of “Pride and Prejudice and Word Embedding Distance”; Michael Gavin, “The Arithmetic of Concepts: A Response to Peter de Bolla”, Sept. 18, 2015; Ben Schmidt, “Vector Space Models for the Digital Humanities”, Oct. 25, 2015.
6. See Elaine Freedgood and Cannon Schmitt, “Denotatively, Technically, Literally,” Representations 125.1 (Winter, 2014), 1-14; and Henry Turner, The English Renaissance Stage: Geometry, Poetics, and the Practical Spatial Arts, 1580-1630 (Oxford: Oxford University Press, 2006), 114-154.
7. The model was trained on context windows spanning 5 words on either side of a given term, for words appearing at least 40 times in the corpus. I removed stopwords (using the standard nltk stopword list), but I did not stem or lemmatize the corpus. The model and a csv of the model contents can be downloaded here. Since I created the model, the Visualizing English Print team has publicly released a version of the EEBO-TCP corpus with standardized spelling, which, I expect, would produce a more accurate model for word sense disambiguation.
8. For arguments supporting count-based approaches to semantic modeling, see Omer Levy, et al., “Improved Distributional Similarity with Lessons Learned from Word Embeddings,” Transactions of the Association for Computational Linguistics 3 (2015): 211-225; Omer Levy and Yoav Goldberg, “Linguistic Regularities in Sparse and Explicit Word Representations,” Proceedings of the Eighteenth Conference on Computational Language Learning (2014): 171-180. For the rationale behind predictive modeling, see Marco Baroni, et al., “Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors,” Proceedings of Association for Computational Linguistics (2014); as well as the paper that introduced the word2vec algorithm, Tomas Mikolov, et al., “Efficient Estimation of Word Representations in Vector Space,” (2013), http://arxiv.org/abs/1301.3781.
9. There is still a lot work to do in using word distribution models to analyze phrases and sentences. Word2vec has been used to identify words that tend to appear in phrases. See Mikolov, et al., “Distributed Representations of Words and Phrases and their Compositionality,” (Oct., 2013). Yet I have not seen persuasive results in using such models to analyze sentence similarity. My own attempts to use word2vec to analyze sentence similarity in the EEBO-TCP corpus has not worked at all. My standard deviation measure represents a somewhat crude but effective method for looking at the semantic similarities between words in context windows. I’m sure that there will be additional approaches that might be more useful in the future. Here’s just some information on results from using the measure in this experiment. The mean standard deviation value for each word in the subset 1678-1682 corpus (averaged across all of the context windows of each word) is 0.11229. The mean for the top 150 terms that I present here is 0.139412, which is a little more than five standard deviations above the mean. While these terms stand out from the rest, it is of course true that there is only a relative difference between the lexical variation appearing in the context windows of the top terms and those of the rest of the words in the model. Above I focus on the contexts of the top terms, but the terms with the lowest values for the measure also indicate its efficacy. For instance two of the bottom terms are oge and ordeining, which like many of the top terms are difficult to contextualize at first glance. In the subset, Oge primarily occurs in Irish genealogies in which formulaic phrases appear with great frequency, and the resulting context windows contain a lot of repeated words. Similarly, ordeining largely appears in formulaic phrases in religious texts, most notably the power of ordeining others. For a prime example, see Henry Dodwell, Separation of churches from episcopal government, as practised by the present non-conformists, proved schismatical from such principles as are least controverted and do withal most popularly explain the sinfulness and mischief of schism (London: 1679). Finally, using my subsetting method produces the additional issue of reducing the size of the corpus under analysis and thus allowing texts with idiosyncratic linguistic structures to dominate. The subset corpus contains 4,370 texts. I think working with count-based distribution models might make this problem easier to avoid, although it may introduce other challenges regarding the size of the model.
10. Roland Barthes, “The Reality Effect,” The Rustle of Language (Berkeley and Los Angeles: University of California, 1989), 141.
12. K. G. Davies, The North Atlantic World in the Seventeenth Century (Minneapolis: University of Minnesota Press, 1974), 157.
13. Bruno Latour, “Circulating Reference: Sampling the Soil in the Amazon Forest,” Pandora’s Hope: Essays on the Reality of Science Studies (Cambridge: Harvard University Press, 1999), 24.
14. Arielle Seiber and Henry Turner, “Mathematics and the Imagination: A Brief Introduction,” Configurations 17 (2009), 12.